
Features for gaining a better understanding of what happens under the hood of C# .NET Core Lambda function

After describing how to set up and deploy a C# .NET Core AWS Lambda function, let’s review some underlying features of this service so that you can produce more of it in deployment phase and while it’s on the air.
TL;DR
In short, for those who are pondering whether to continue reading or not, the gist of this post:
- Altering the Lambda function’s deployment parameters
- Using environment variables
- Input and output of Lambda function (C# objects, using .NET SDK)
- Logging
- Testing the Lambda function
Before we begin…
Before diving into the deep water, to produce the benefit from this blog-post, you should be familiar with Lambda function concepts and have an AWS Explorer installed in your Visual Studio. Furthermore, you’d better obtain .NET Core version 2.1.3 or above.
If you haven’t experienced Lambda function based on C# .NET Core so far, then you can follow my previous blog-post and catch-up.
Preparations: Setting the permissions
Secondly, setting the environment can be a bit tricky, especially setting the permissions. You need to grant the relevant permissions for the user that deploys your Lambda function. Without proper permissions, uploading and deploying the Lambda function through the AWS Explorer in your Visual Studio will fail.
You can find below an example of a tailored policy for granting permissions to a specific Lambda function. The specific Lambda function’s ARN appears in the Resource field since we want to limit the access to a specific Lambda function rather than open the access to all functions. This security boundary is useful to gain more control over your policies and authorisations.
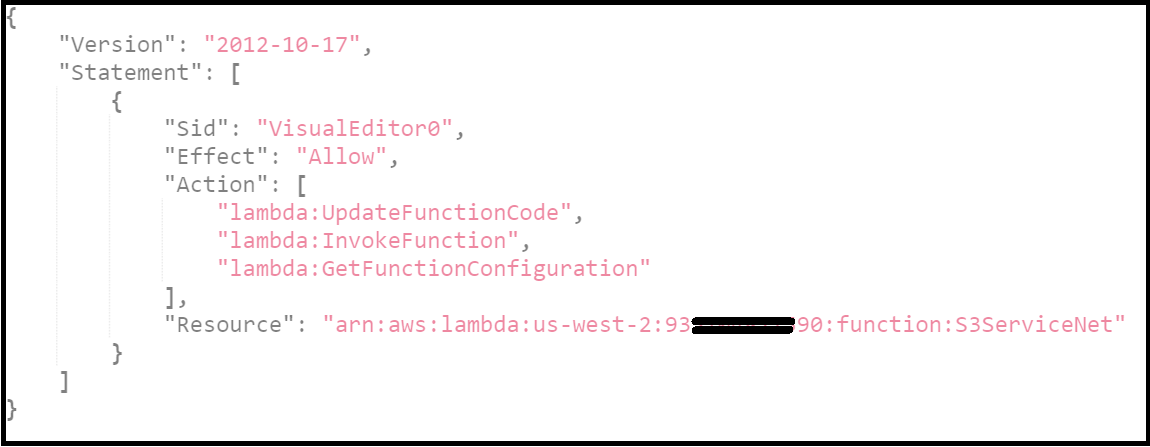
A side note, if you didn’t grant permissions for other functions, you might get an error message when trying to explore them via the AWS Explorer. So, you can change the policy above and grant permissions to other Lambda functions or create more policies and associate them with the IAM role.

Lastly, you need to create an IAM role with adequate permissions to run the Lambda function and its dependencies. For example, if your function needs to access S3, define a role with S3 permissions.
Once you have set the permissions successfully, you are ready to go!
1. Deployment parameters
The Lambda function’s deployment definitions are stored in the file aws-lambda-tools-defaults.json, which is part of the C# project. This file includes basic settings of our Lambda function, for example, the profile of the user that deploys the service, runtime environment, function’s name, the IAM role that runs the function and more.
Some of these variables are displayed in the AWS Publish wizard as well. If you change the variables in the wizard as part of the deployment process, you can opt for saving these changes back to the JSON configuration file:

The deployment is based on CLI command line behind the scene. In fact, this file contains the optional arguments for the command dotnet lambda deploy-function <Function_Name> [options].
Using the command “dotnet lambda” requires .NET Core 2.1.3 or above installed in your machine. You can install Lambda package with the command:
dotnet tool install -g Amazon.Lambda.Tools. Running the commanddotnet lambda deploy-function helpdisplays all possible variables for the Lambda function’s deployment. You can plant these variables in the JSON configuration file.
Example: setting the Lambda function’s subnet
Let’s set a subnet to our Lambda function by adding a new parameter to the configuration file. The parameter holds the subnet’s identifier. This value will be an input for the AWS Publish wizard. Our configuration file should look like that:
{
"profile": "user1",
"region": "us-west-2",
"configuration": "Release",
"framework": "netcoreapp2.0",
"function-runtime": "dotnetcore2.0",
"function-memory-size": 512,
"function-timeout": 15,
"function-handler": "StorageService::StorageService.ServiceHandlerFunction::LambdaHandler",
"function-name": "S3ServiceNet",
"function-role": "arn:aws:iam::1112223334445:role/S3-lambda-Role",
"tracing-mode": "PassThrough",
"environment-variables": "",
"function-subnets": "subnet-00bd6XXXXXXX"
}
You might encounter the following error: “Error updating configuration for Lambda function: The provided execution role does not have permissions to call CreateNetworkInterface on EC2”. The origin of this error is lack of permissions for the IAM role that runs the Lambda function ( S3-lambda-Role in the JSON above). Since the Lambda service needs access to VPC’s components, it requires more permissions than before.
To overcome this error, I created a policy that consolidates all the necessary EC2 permissions and attached it to the IAM role. It’s much cleaner to arrange and assign permission by creating a policy since this policy can be attached to other roles in the future as well.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"ec2:CreateNetworkInterface",
"ec2:DescribeNetworkInterfaces",
"ec2:DeleteNetworkInterface"
],
"Resource": "*"
}
]
}
Once the IAM role obtained these permissions, the Lambda function can be deployed successfully.
2. Using Environment variables
Using environment variables is a common practice to consume different variables based on the deployed environment. AWS supports this pattern in Lambda function as well, so you can define and consume environment variables based on key-value pairs.

You can configure environment variables as part of the deployment process or afterwards when the Lambda function has already been deployed.
Configuring environment variables before or during the deployment process
The environment variables are stored in the JSON configuration file of the C# project (aws-lambda-tools-defaults.json).

The variable is called environment-variables, its format is: “<key1>=<value1>;<key2>=<value2>;”.
Saving values in the configuration file assures they will be deployed together with the Lambda function. If you have configured other variables in the Lambda function console, these existing variables will be overwritten by the variables that were defined in the deployment process.
Another way to define environment variables before deploying the Lambda function is via the AWS Publish wizard. The wizard’s second screen contains a section in which you can add/remove variables. In fact, these are the same variables that were configured in the JSON configuration file. You have the opportunity to amend them before deploying the function.
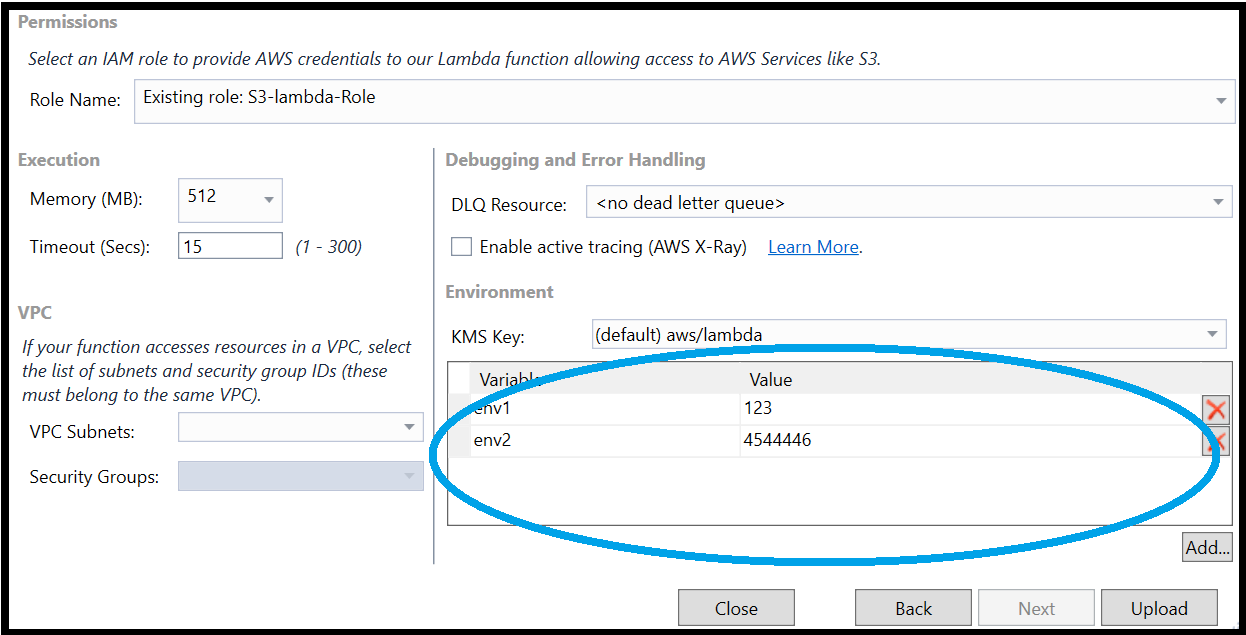
Configure environment variables after deploying the function deployment
Accessing the environment variables online is done via the Lambda function’s management screen, below the Function Code section.
The AWS Explorer, in the Visual Studio, is another way to access and amend these variables. After selecting the Lambda function from the explorer navigation, under the Configuration section, you can find the environment variables. This screen enables saving the changes you’ve done by clicking on the “Apply Changes” button.
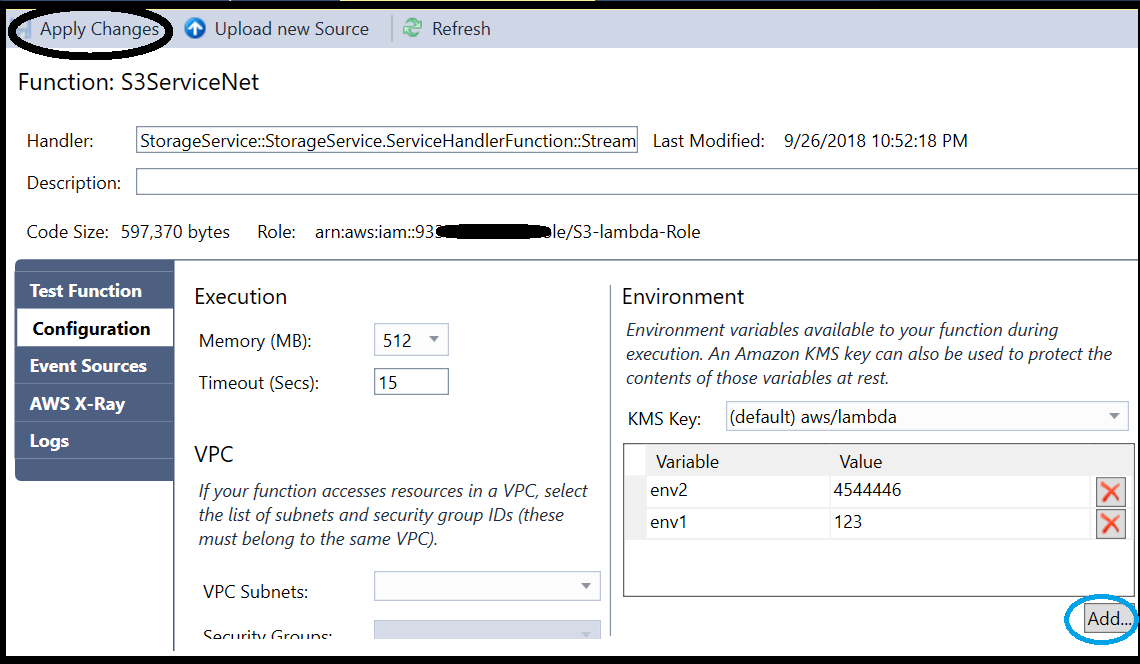
On a side note, this is an intuitive and friendly user interface for changing other Lambda function’s variables, not only the environment variables. Sometimes, I find it more user-friendly than the AWS interface.
Consuming the environment variables
Consuming the environment variables as part of the Lambda function’s logic is done intuitively in the C# code, by using the System library:
System.Environment.GetEnvironmentVariable(<key>);
3. C# Lambda handler method signature
Lambda function execution is trigger-based. The function receives JSON input and returns an output that is based on the invocation source type. The input includes relevant information about the source that triggered the function. Whereas the output provides the necessary status of the execution. For example, the JSON input for S3 source includes relevant information about the bucket and the file that triggered the function and the operation (PUT, DELETE).
Input parameters
A generic signature of C# method for Lambda service handler includes two parameters: a Stream object and ILambdaContext interface:
Assuming the trigger is API Gateway, the invocation of URL ‘https://<URL>/<GW-name>/S3ServiceNet?param1=111¶m2=222’ will produce the following JSON input (I altered some fields to avoid disclosure of sensitive data), in which you can see the query parameters inside.
{
"resource":"/S3ServiceNet",
"path":"/S3ServiceNet",
"httpMethod":"GET",
"headers":null,
"multiValueHeaders":null,
"queryStringParameters":{
"param2":"222",
"param1":"111"
},
"multiValueQueryStringParameters":{
"param2":[
"222" ],
"param1":[
"111" ]
},
"pathParameters":null,
"stageVariables":null,
"requestContext":{
"path":"/S3ServiceNet",
"accountId":"9337048219888888888",
"resourceId":"x6ya4u",
"stage":"test-invoke-stage",
"requestId":"60f456ad16-c003f-131e8-bd034-ab017b3b1faeb",
"identity":{
"cognitoIdentityPoolId":null,
"cognitoIdentityId":null,
"apiKey":"test-invoke-api-key",
.........
},
"resourcePath":"/S3ServiceNet",
"httpMethod":"GET",
"extendedRequestId":"XXXXXXXXXXXX=",
"apiId":"XXXXAASSWWEE"
},
"body":null,
"isBase64Encoded":false
}
C# Object Request Example
AWS provides C# objects that wrap the common triggers’ input, such as S3 and API Gateway, so instead of parsing the JSON input, you can easily interact with a C# object.
It can be demonstrated clearly by reviewing object APIGatewayProxyRequest (under Amazon.Lambda.APIGatewayEvents namespace), which represents the input of API Gateway. It holds a property named RequestContext (its namespace APIGatewayProxyRequest.ProxyRequestContext), which has a property titled Identity.
If you find this hierarchy and names familiar, then you have a good short term memory, since this is exactly the same JSON input above 👆.
Output Parameters
Similarly to the input, the response varies depending on the trigger’s type. AWS C#.NET Core libraries include tailored response objects based on the trigger.
For example, the expected response for API Gateway call is the object APIGatewayProxyResponse, whereas the expected response for S3 trigger is a simple String. If our method returns a different object type than expected, the invocation of the Lambda function will fail and throw the following error:
Execution failed due to configuration error: Malformed Lambda proxy response
A valid C# method for handling an API Gateway trigger should receive Stream or APIGatewayProxyRequest object and return APIGatewayProxyResponse:
APIGatewayProxyResponse LambdaHandler(APIGatewayProxyRequest input, ILambdaContext context)
You can find more about the AWS C# library in its GitHub project. Reviewing this code will shed more light about the objects’ structure and how to use this library (aws/aws-lambda-dotnet).
Serialising from Stream to AWS C# Objects
The .NET library mentioned above also provides a JSON serializer class that facilitates the serialisation and deserialization of Lambda request and response objects. The serialisation logic is based on the open-source library Newtonsoft.Json.
Being able to deserialise the input stream gives you the flexibility to define a general handler signature that receives a stream and returns an object, while the specific logic can be based on the trigger’s input.
You should note that deserialization of a mismatched object doesn’t throw an exception, therefore better check the deserialised object’s properties before using them as part of your logic.
More about the Lambda function’s parameters
Reading my post “Controlling and Manipulating AWS API Gateway Request Parameters” can shed more light about manipulating requests on the API Gateway level (before reaching to the Lambda function).
4. Logging
AWS provides an API for logging via the interface ILambdaContext, which exposes a Logger property (type ILambdaLogger).
The object ILambdaLogger has two methods for logging: Log and LogLine. The log messages are written into AWS CloudWatch log trails, as part of the other AWS log messages related to the function’s execution. The individual log streams are located under a log group, by default, its name is “/aws/lambda/<function_name>”.
The object ILambdaContext exposes read-only properties that hold the log group name (ILambdaContext.LogGroupName) and the current log stream ((ILambdaContext.LogStreamName)). The log stream is a rolling file since messages are continuing to append it every time the Lambda function is invoked. However, a new log stream is created for each version.
A note: to being able to write successfully to the log can be made if the executing IAM role of the Lambda function has access to CloudWatch. By default, the AWS policy arn:aws:iam::aws:policy/AWSLambdaFullAccess already includes this permission, but if you have configured a tailored policy, it may lack it.
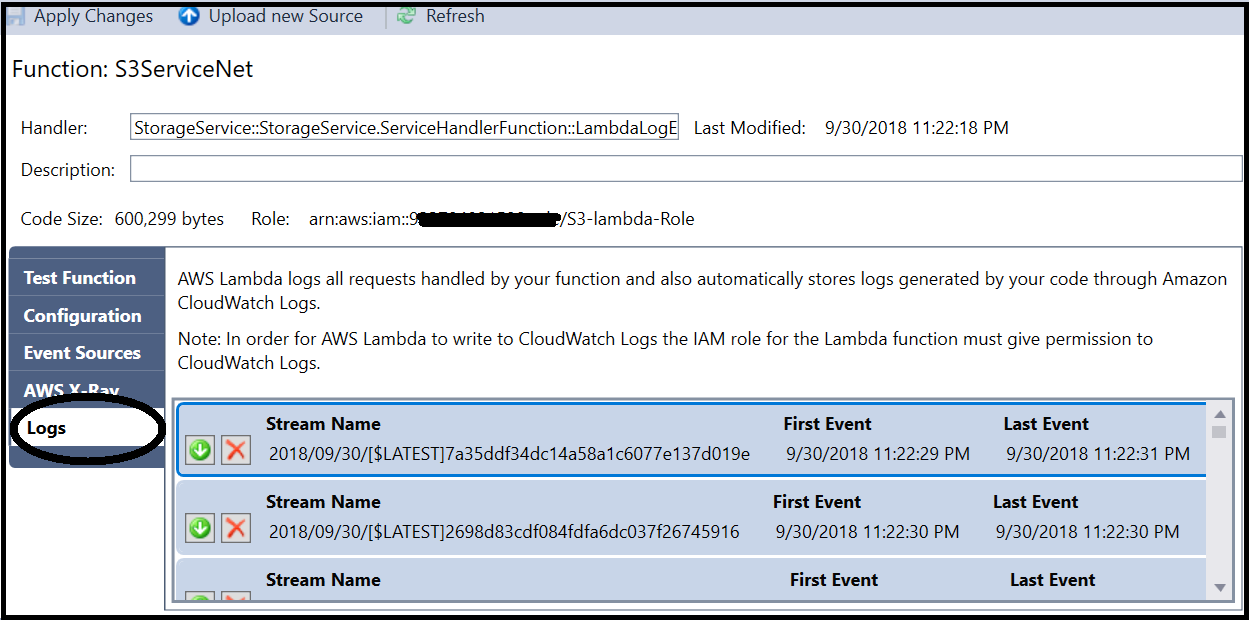
Accessing the Lambda function’s logs
The CloudWatch logs are accessible via the AWS Lambda function management console, under the Monitoring tab. CloudWatch interface provides useful features, such as filters and retention definitions.
Another way is accessing the logs from the AWS Explorer in Visual Studio. As opposed to the AWS CloudWatch interface, the logs must be downloaded in order to view them. Therefore, to gain a better understanding of the function’s activities and events, as well as utilising the full capabilities set, it’s easier to use the CloudWatch native user interface.
5. Testing the Lambda function
So, after grasping the concepts of the Lambda function’s input and output and writing log messages, you have the necessary knowledge required to test our function efficiently.
Testing the function in the Lambda Console doesn’t require invoking any trigger. Since each trigger is represented by a different JSON format, you can check the logic by simulating the trigger’s input. AWS provides predefined templates for each trigger.

You can save the template and alter its content to extend the simulated test cases. For example, if your function’s logic depends on the APIGateway parameters, you can set these parameters in the JSON input. You can also stimulate the trigger’s action (GET, PUT, DELETE, etc.), as it’s included in the input stream as well.
After running the function, you can check the output. Since you have written adequate logs, you can investigate your function easily.
Let’s take an S3 trigger as an example. Assuming your function is triggered when a file was added to an S3 bucket (PUT event). You can stimulate this event by assigning the bucket name and file name into the following input:
{
"Records": [
{
"eventVersion": "2.0",
"eventSource": "aws:s3",
"awsRegion": "us-west-2",
"eventTime": "1970-01-01T00:00:00.000Z",
"eventName": "ObjectCreated:Put",
"userIdentity": {
"principalId": "EXAMPLE"
},
"requestParameters": {
"sourceIPAddress": "127.0.0.1"
},
"responseElements": {
"x-amz-request-id": "EXAMPLE123456789",
"x-amz-id-2": "EXAMPLE123"
},
"s3": {
"s3SchemaVersion": "1.0",
"configurationId": "testConfigRule",
"bucket": {
"name": "<bucket-name>",
"ownerIdentity": {
"principalId": "EXAMPLE"
},
"arn": "arn:aws:s3:::<bucket-name>"
},
"object": {
"key": "<file-name>",
"size": 1024,
"eTag": "0123456789abcdef0123456789abcdef",
"sequencer": "0A1B2C3D4E5F678901"
}}
}]}
Using AWS Explorer for testing
The same concept applies by invoking tests from AWS Explorer; however, this user interface doesn’t expose the saved test scenarios. Maybe it will be added in a newer version.
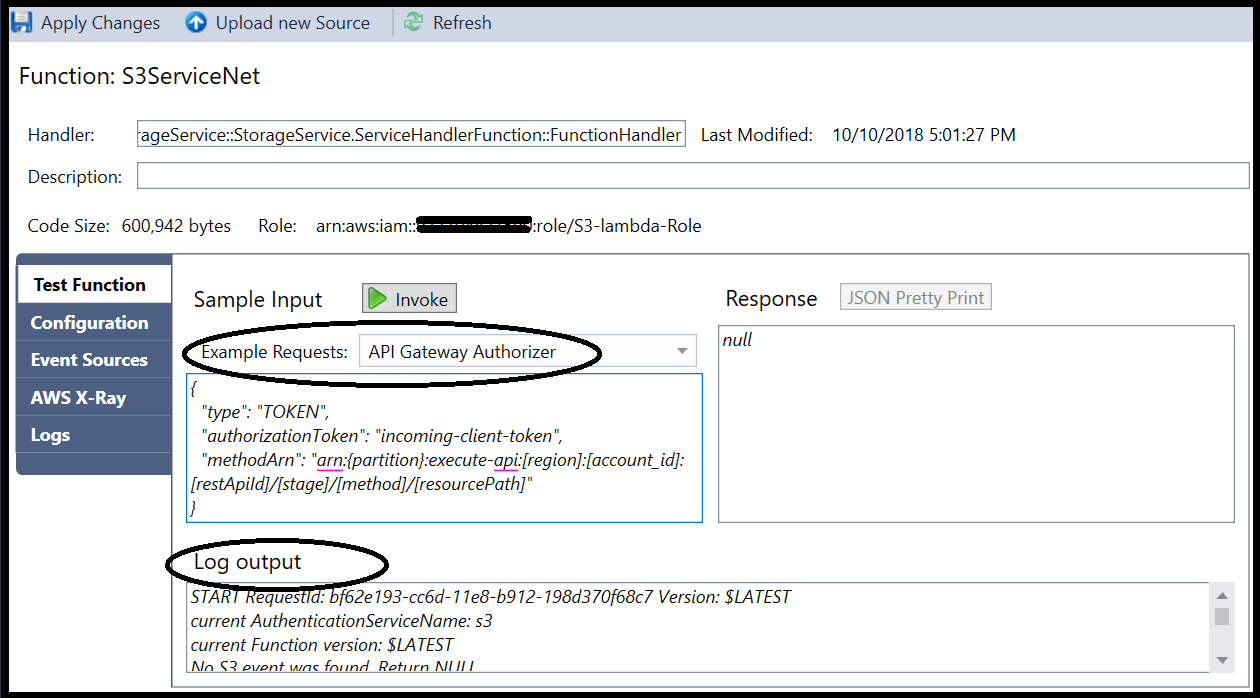
Wrapping-up
There is more about the integration between the API Gateway and the Lambda function. Requests can be validated and manipulated on the API Gateway level, you can read more about it in another post: “Controlling and Manipulating AWS API Gateway Request Parameters”.
It always feels satisfactory to reveal what’s behind the scenes. Understanding the underlying layers of Lambda service can be beneficial for using it more efficiently. I hope you felt it while walking through this post.
Thanks for reading! If you liked it, give it some love by pressing on the 👏 button! Feel free to comment and highlight as well.
Keep on coding 😎.
– Lior

Like!! Thank you for publishing this awesome article.